 数据科学人
数据科学人
本周的主题是 Decouple 解耦。
在政治经济学中,decouple 的含义是「脱钩」,一方不以另一方为锚。软件工程中,系统通过解耦来降低系统组件之间的依赖程度。
众所周知,在微服务架构中,我们可以对任何一个服务进行调整,而不影响其他服务。不同服务在迭代时可以免受其他部分的干扰,自主性更强,变化速度更快。我们也可以随时更换掉某个组件,不而用担心影响整个系统的稳定性,和带来额外的工作。
在使用早期的阶段,高度整合的打包方案省去了我们寻找多个解决方案的需要,但一刀切的方案往往在任何部分都不突出,随着使用的深入,我们会逐渐去寻找那些更模块化、也更强大的方案。
Kubernetes 这样新技术的出现,也让整合软件栈带来的好处变得没那么明显的了。
以下是本周的推荐。
1.Why Best-of-Breed is a Better Choice than All-in-One Platforms for Data Science
数据科学的工具类产品可以分为两大类:一类是以亚马逊的 Sagemaker 和 Databricks 为代表的「一站式平台」,另一类是专注于数据科学和机器学习过程一个方面的「最佳产品」,如 Kafka 和 Snowflake。Matthew Rocklin 和 Hugo Bowne-Anderson 认为「最佳产品」是更好的选择。
「一站式平台」将许多工具集合在一起,因此可以为常见的工作流程提供一个完整的解决方案,相反,「最佳产品」专注于做一件事并把它做好,在这件事上它们通常能更有效地满足终端用户的需要,「最佳产品」更容易操作,也更便宜,相比之下,「一站式平台」在工作流的任何部分都不够出色。
其次,数据科学和机器学习的世界比发展速度非常快,「一站式平台」过于庞大和僵化,很难保持所有组件都快速变化,而「最佳产品」行动迅速并且推动着技术的变革。
在我上两期 Newsletter 中提到过的大数据平台供应商 Cloudera 就是一个典型的代表,在 Spark 2.0 发布后的几年中 Cloudera 一直在运行 Spark 1.6:
任何试图建立一个放之四海而皆准的综合平台的尝试,都必须包括非常广泛的功能,每个功能中都必须提供非常广泛的选择,以至于维护和保持更新将是非常困难的。 当你想纳入实时数据反馈时会发生什么?当你想开始分析时间序列数据时会发生什么? 是的,一体式平台会有工具来满足这些需求。但它们是你想要的工具吗?如果有别的选择,你会使用其他工具吗?
2.Designing An Analytics Stack Like We Design Software
Mode 的布道师 David Wallace 提议数据基础设施在设计时,应当借鉴软件开发领域中最重要的原则「松耦合」——对一个有界的上下文进行变化时不需要其他变化。
例如,在微服务架构中,我们可以对一个服务进行调整而不影响其他服务。越来越多的开源软件和 C 端软件在设计中体现了这种原则,以模块化但互补的工具形式出现,为独立问题提供优雅且强大的解决方案。
这里的关键词是「有界」,换言之,所有工具必须意识到自己在一个更大的工具生态系统中,它们是为整合而设计,而不是孤立地进行设计。它反映了一种进步的心态,它假设我们今天使用的技术会过时,需求也会发生变化。
We should not fool ourselves into believing that today’s solution will be right for tomorrow. Instead, we should embrace change and plan for it accordingly.
我们不应该欺骗自己,相信今天的解决方案会适合明天。相反,我们应该拥抱变化,并为之制定相应计划。
Wallace 借用了《构建微服务》的作者 Sam Newman 的话:
... our architects need to shift their thinking away from creating the perfect end product, and instead focus on helping create a framework in which the right systems can emerge, and continue to grow as we learn more.
……我们的架构师需要将他们的思维从创建完美的最终产品转移到帮助创建一个框架,在这个框架中,正确的系统会出现,并随着我们的学习不断成长。
3.The Data Engineering Megatrend: A Brief History
这篇博客介绍了从 2000 年到 2020 年数据工程的发展史,讲述了今天企业数据孤岛问题的由来,作者来自 RudderStack 团队。
首先,他提到了一本叫《凤凰项目》的书,这本书描述了当代美国企业 IT 部门和其他团队之间的分裂,在数据的世界中也存在这种现象。一个典型的例子是 IT 部门提供的数据仓库和 ETL 管道,已经无法满足营销部门对数据的需求。
「最佳产品」比起「一站式」解决方案更加先进,比如 Salesforce + Marketo 比 Salesforce 营销云更好用,但同时也带来了数据孤岛的问题,每个团队都有自己的数据,它们分散在独立的第三方系统中。2017 年 MarTech 领域工具的数量从 150 个工具爆炸式地增长到 5000 个。
Non-IT teams faced a similar problem. Having point solutions was great for individual teams. However, the inability of those tools to talk to each other was problematic. The classic example here is connecting the dots between marketing software and sales software (and don’t forget the warehouse!), which became a huge industry in and of itself.
下面这张图让我想起了著名的康威定律。每个人都得到了自己想到的软件,但同时又希望数据能够互通,在这样的背景之下,数据工程又重新被人们提起。
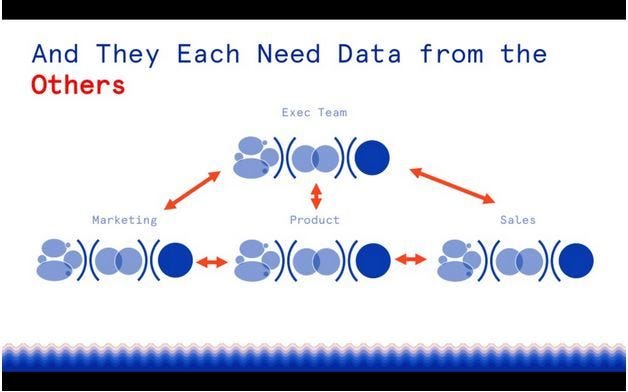
4.Data’s horizontal pivot
这篇来自 Benn Stancil 的 Newsletter 中,他借用了经济学中的「横向整合」的概念来比喻数据产品的这种解耦。
在一个领域中,「纵向整合」的公司同时拥有产品的整个供应链和分销网络,例如一家啤酒厂商同时拥有:植啤酒花的农场、酿酒厂、运输啤酒的卡车和酒吧。而「横向整合」的厂商,并非通过扩展自己的链条到其他部分进行扩张,而是通过增加自己所在环节中的市场份额。
十年前的 BI 产品以「纵向整合」为主,典型的代表是 Qlik 和 Tableau,它们不仅提供了可视化分析功能,还提供了数据摄取的能力,甚至还可以利用它们对数据进行建模。
「横向整合」是新的趋势,人们不再依赖 Google Analytics 和 Salesforce 这些工具中的原生报告功能,而是将它们导入中央仓库,在那里进行分析。
有两个主要的原因,一个是过去十年数据生态系统的工具数量骤增,端到端的供应商很难跟上步伐,新技术层出不穷,但当下很难判断哪些技术是糟粕,「纵向整合」的产品很容易变得臃肿;另一个是前面提到的数据互通性问题,产品团队和销售团队可能使用不同的工具,在这种情况下,分析师希望所有的报告都建立在相同的技术和逻辑上。
5.Here is What Happens If You Decouple Your BI Stack
本文介绍了一种以 API 的形式对 BI 进行解耦的方法——将仪表盘分解为单独的图表、指标,在各种报告中重复使用,它也被称作 Headless BI。
它有以下几个优点:
- 以在不同的仪表盘上重复使用相同的组件。
- KPI 只需要被定义和更新一次。
- 防止重复工作,如果有人已经创建了一个特定的指标并分享了它,我们可以避免第二次建立它。
- 通过共享相同的指标定义,我们可以为分析提供一个单一的真理来源,因为减少了一个 KPI 在多个地方有不同定义的风险。
除此之外,由于背后是一个基于 API 的微服务架构,这种方法很容易生成一个自定义的嵌入式分析应用。
Project of the Week
Segment 公司创业初期的产品 analytics.js ,可能是第一个解耦数据层和工具层的项目,在使用多个数据分析工具的情况下,简化数据收集过程。2013 年这个项目在 Hacker News 上启动时只有 400 行代码,它的 landing page 非常简单,但解决的问题也非常痛:

Book of the Week
《凤凰项目》是 Gene Kim 在以小说笔法写的一本 IT 管理类读物,是公认的 DevOps 圣经。小说描写了主人公比尔临危受命,接任公司 IT 运维经理一职,此时公司经历了多轮裁员,线上问题不断。尽管困难重重,比尔仍尝试出了一套新的 IT 转型方案,整个转型过程就像我们从传统开发模式转型 DevOps 开发模式一样,他从中总结出了很多道理,如二八定律(线上 80% 的故障来自于 20%的变更)和著名的三步工作法。
以上是本周 Newsletter 的推荐,希望对你有用。
下周见。
Dreamsome
❤️ 想支持《数据科学人》?把它推荐给 3 个朋友吧!
🚀 欢迎用电邮订阅《数据科学人》,我将以周报的形式发布内容