 数据科学人
数据科学人
本周的主题是 Metadata 元数据。
Alan Kay 说过:「在协商重要的事时我们不会发电报,而是派大使去谈」。如果我们在传送数据的时候不发送解释器,那么收到数据的人就无法正确地解读数据。
元数据就是对数据的解释器,它是关于数据的数据,很多时候我们感觉不到元数据的存在,很有可能是因为它以背景知识的形式出现,而非结构化信息。
有了结构化的 metadata,不仅可以让不同的系统相互操作,还能够在不同人和角色之间形成共识,避免无效的沟通。相反,如果缺少必要的元数据,使用数据的人也需要花更多时间来验证数据、排查问题。
Kevin Kwok 在 The Arc of Collaboration 指出「协作与生产力有密切的联系」,有越来越多的生产力工具(Figma 和 Notion)通过把协作放入生产循环,来缩短反馈路径,越来越多的数据工具除了完成自己的核心任务,也都试图向用户暴露更多的 metadata。
当企业分析的对象从静态的数据集变为从各个地方源源不断地摄取并转换的「大数据」,元数据不仅仅描述了数据本身的形状,还描述了数据是如何产生的。
1. The 3 Things to Keep in Mind While Building the Modern Data Stack
今天建立起一个分析堆栈比以往任何时候都容易得多,数据团队面临的新挑战是如何制定高效的工作流程,让不同角色跨工具进行协作。下图反映了当一个仪表盘出现错误时,调查它经历的全部过程,其中涉及了四种工作角色,在最坏情况下一共需要在五个工具中的检查结果——业务方在仪表盘里发现蹊跷,分析师看了 SQL 以后发现问题不在自己这边,跑去找工程师,工程师在数据平台的日志里一通翻找,最后发现是同步数据侧出了问题……怎么听都像上周刚刚发生过的故事。
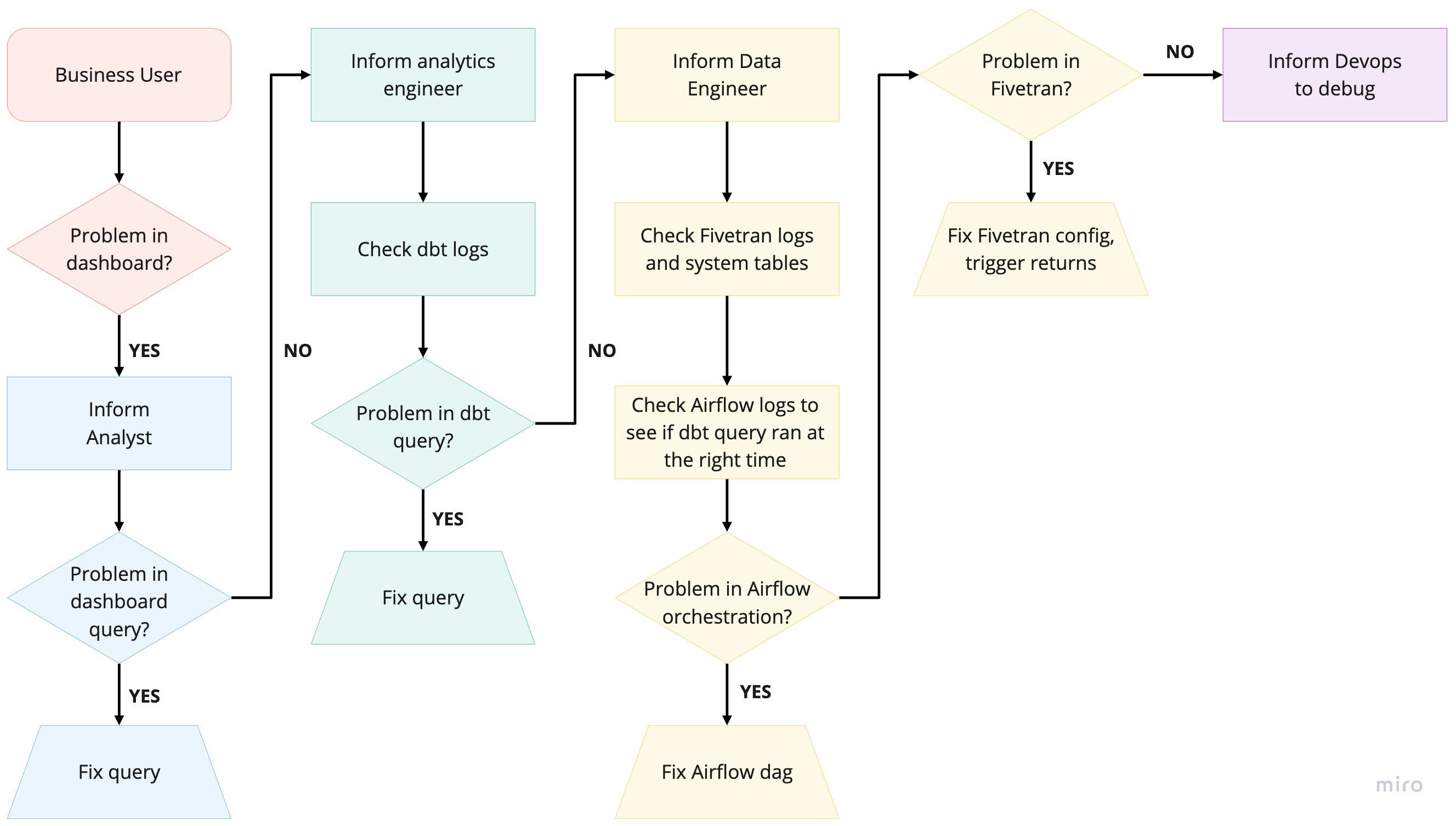
本文的作者是 Raghotham Murthy,他提出了一个三层框架对 data stack 上的工具进行拆解,分别是:a) 数据层、b) metadata 层和 c) 界面层。这个框架可以帮助我们有意识地挑选工具,弄清楚工具之间如何配合,并设计出更容易协作的数据平台。
首先,不同系统的核心差异主要体现在数据层,这是数据流真实发生的地方,例如 Snowflake 是数据的存储与计算,dbt 是数据的转换,Fivetran 是数据的移动,Looker 则是数据的可视化。
其次,metadata 层是关于数据流的数据,包括数据结构(schema)、数据之间的关系(血缘)、编配(orchestration)和其他管理类数据(权限、审计、运行状态)。不同工具在 metadata 层往往各有侧重,但同时又有很大交叉和重叠。例如 Looker 提供了schema、访问控制以及血缘;Snowflake 中有 schema、访控,但没有血缘;Fivetran 会显示 schema 和审计日志;dbt 提供了 schema、血缘、审计和运行状态,但没有编配和访问控制;Airflow 中有编配和运行状态,但没有 schema 和访控。
最后,界面层是操作数据层的用户界面,为了优化效率,不同工具都有自己专门的界面层,因此数据团队在处理数据流的不同部分时,有时不得不在不同工具之间切换。
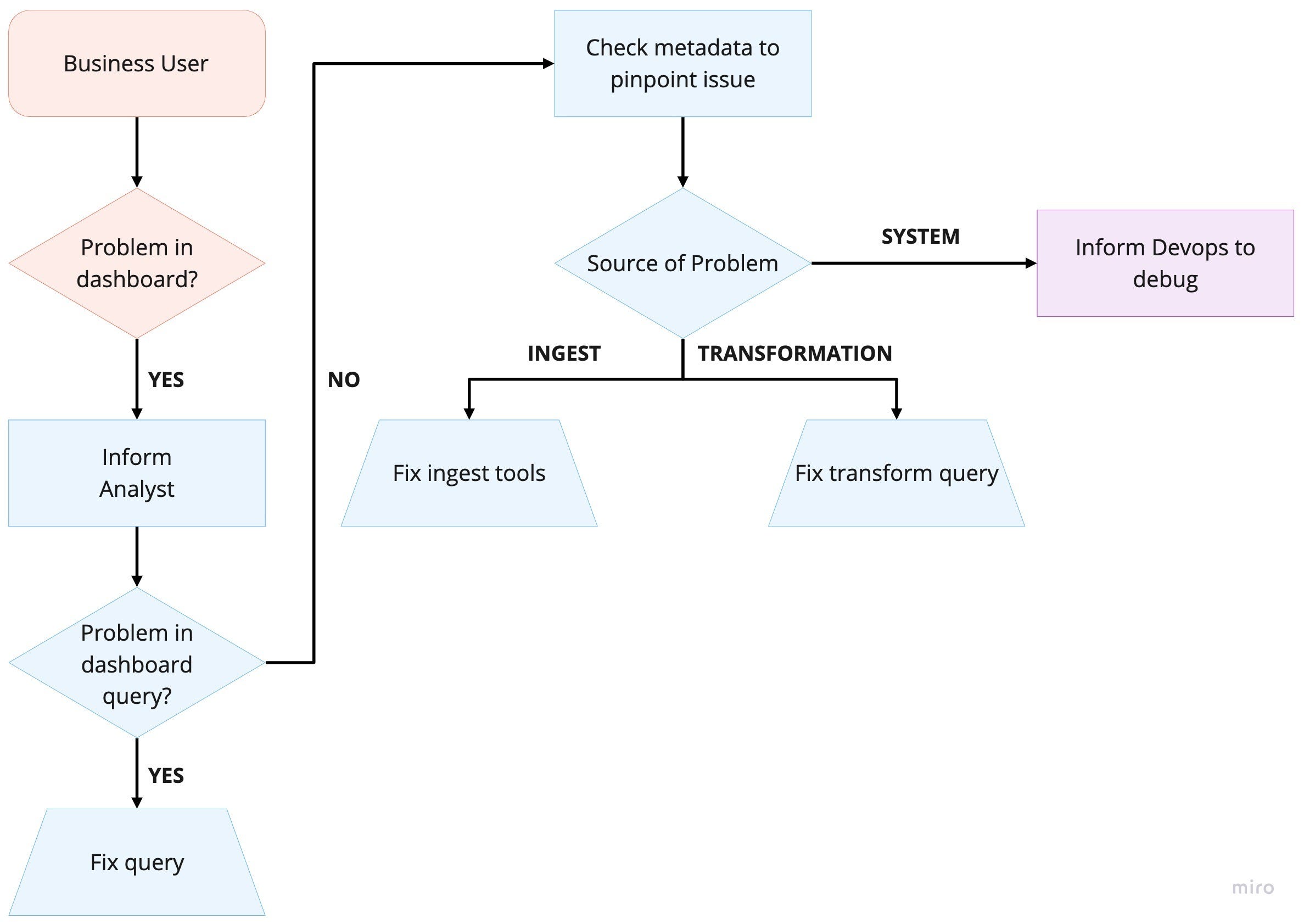
Murthy 使用这个框架来设计他们公司的数据栈,其核心想法是围绕中央 metadata 来搭建数据流:用元数据驱动 orchestration,同时将获取元数据的接口标准化,接入所有内部工具的界面层,这样就能让分析师和数据工程师共享相同界面,从而快速定位问题,简化后的工作流如下图:
2. The data production-consumption gap
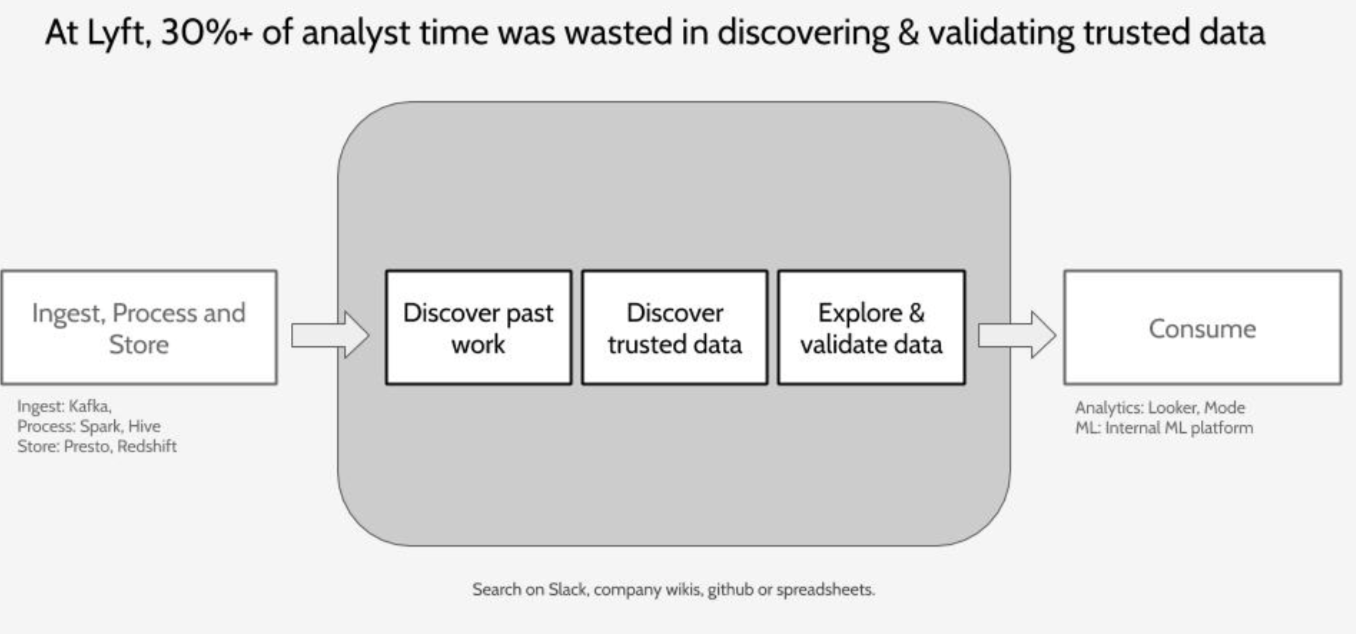
本文的作者是前 Lyft 的工程师 Mark Grover。数据存储、摄取和处理技术的创新让数据生产变得更容易了,但消费者却因为不知道它们的存在,而不得不把时间花费在找寻数据的过程中。在 Lyft,分析师有超过 30% 的时间被浪费在寻找可信数据和验证数据的可信度上:
- 
以 Lyft 这样的现代数据组织为例。当一名数据科学家正在创建一个新版本的 ETA(预计到达时间) 模型时,他们必须根据现有的模型来验证其性能。在像 Lyft 这样的公司,至少有 50-100 个与 ETA 相关的列,通常分布在不同数据仓库中。ETA 的真实来源是什么?它是否还在被更新?它是如何计算的?谁在使用它?多长时间被更新一次?通常如何被使用?这些问题随时间而沉淀。这还只是表面问题,还没考虑到同样的数据可能有不同来源(例如,来自不同的地图供应商的 ETA),在不同的情况下意味着不同的东西(在打车前测量的 ETA,在乘车过程中测量的 ETA,或实际的 ETA),有不同的用途(显示给司机或乘客看的 ETA 还是喂给算法的 ETA)。这对数据科学家来说是门槛,对数据工程师而言是干扰。
Grover 认为企业需要一个 metadata 平台来捕捉以下三种类型的数据:
- Application Context — what & where is the data, its shape/stats, etc.
- Behavior — who produces & consumers this data (humans and programs)
- Change — how has the data and code producing data changed over time?
3. Metadata is Useless — Unless You Have a Use Case
这篇文章来自数据监控工具 Monte Carlo 的 CEO Barr Moses。Moses 说:虽然越来越多的公司开始收集它们的数据的元数据,但很多人见木不见林:
All too often organizations hungering to become data-driven can’t see the forest for the trees: data without a clear application or use case is nothing more than a file in a database or a column in a spreadsheet.
就像没有背景的数据只不过是一堆数字一样,metadata 本身也没有用,它只不过是关于其他信息的更多信息,收集它并不难,但如果没有一个实际的使用案例,元数据没有意义。比如忽略了使用场景的血缘图可视化,尽管它们可能看起来很酷:
Take for example, lineage, a type of metadata that traces relationships between upstream and downstream dependencies in your data pipelines. While impressive (neon colors! nodes! sharp lines!), lineage without context is just eye candy, great for a demo with your executives — but, let’s be honest, not much else.
血缘最大价值在于它可以帮助想要更改某个字段的人理解:如果修改它将会对哪些下游数据(表或报告)产生影响,展示血缘关系的最佳场景是在修改字段定义的编辑器中,而它的后续操作也很可能是对所有利益相关者进行通知。
也就是说 metadata 可以提高系统的可理解性,帮助使用者发现问题、判断影响,以及寻找到需要协作的对象。
4. Moving past Airflow: Why Dagster is the next-generation data orchestrator
开发人员对工具进行咆哮是一种流行,在这篇文章中,Nick Schrock 借用户之口抱怨了 Airflow 的很多问题,比如难以测试、单体部署和无限等待的 Sensor,这些问题也是 Nick Schrock 开发 Dagster 的理由。
Dagster 在设计上有一个和 Airflow 很不一样的点,它认为编配器必须要感知数据,因为比起管道本身,用户更关心管道所产生的数据,而管道的名字和结构其实都是实现细节。
Schrock 说:「团队之间的接口应该是数据产品,而不是管道」。所以 Dagster 除了在自己的 UI 中展示计算任务相关信息以外,还会在展示表的行数、生成时间和依赖关系这些 metadata。
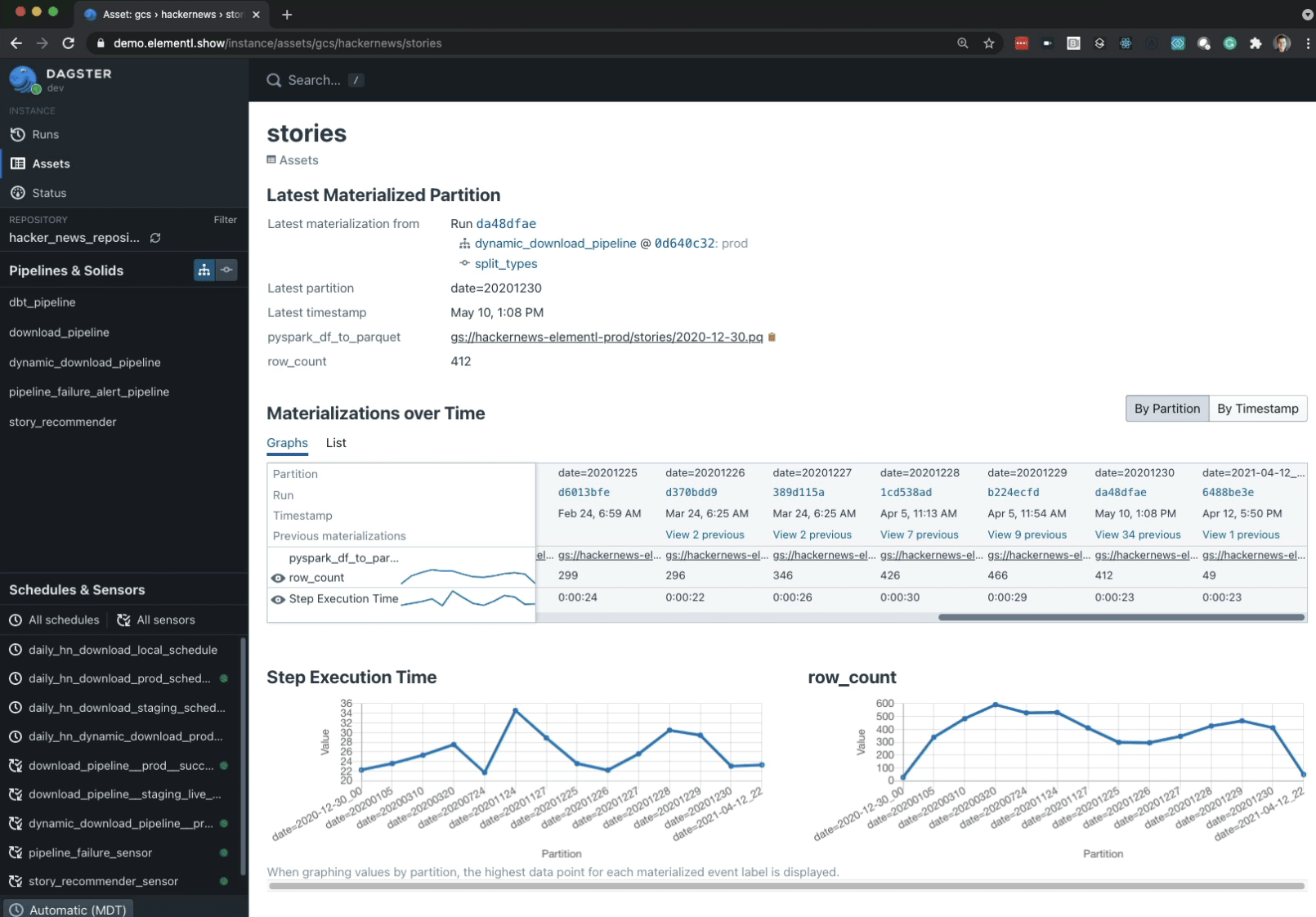
这一点同样印证了今天推荐的第一篇文章中的说法,data stack 上的工具在 metadata 层上会有很多交叉和重合,因为离应用场景更近,metadata 发挥的价值就越大。Dagster 称之为垂直集成,它提供的只是运营层面的目录功能,因此并不会取代其他数据目录(catalog)工具。
Dagster does not seek to replace all data cataloging tools. We view our asset catalog as an operational catalog that takes advantage of vertical integration with the orchestrator. Our vision is to make the catalog the source of truth on the relationships between assets and the computations that produce them, a “single pane of glass” for operational workflows, and link out to data catalog tools for more advanced capabilities.
5. We Failed to Set Up a Data Catalog 3x. Here’s Why.
这篇文章介绍了 Atlan 在创建数据目录过程中的心路历程,历时 5 年共经历了 3 次失败的尝试。
Metadata 其实就是背景,创建数据目录最难的部分在于让非技术人员有添加背景的能力和意愿,用户体验对于这类型产品至关重要,它不仅仅意味着更低的使用门槛,也意味着更高的使用频率。
我们第一次尝试失败的原因是,我们过多地关注技术中很酷很炫的部分,比如由 NLP 驱动的搜索,而不是核心挑战——如何使我们的数据团队能够轻松地为我们所有的数据资产添加「背景」,作为他们日常工作流程的一部分?
我认为数据目录产品是有网络效应的,因为使用的人越多,贡献 metadata 的人也就越多,它的体验就会更好。
没有一个人拥有关于数据的全部背景。有些上下文是以业务为重点的,所以只有业务分析师或利益相关者知道它。有些上下文是技术性的,只有数据工程师知道。还有一些上下文是埋藏在数据深处的,比如某一列的奇怪的异常情况,只有数据分析师知道。
Project of the Week
上个月 Atlan 宣布了 A 轮融资的新闻,他们对自己的形容是数据驱动团队的 Github/Salesforce/Linear/Superhuman,列几个我认为不错的功能:
- 解析数仓里所有 SQL 来推断血缘
- 敏感数据的访问权限会通过血缘进行传播
- 列级别的访问控制
- 使用机器学习算法识别邮箱、信用卡等敏感信息的字段
- 自动对数据进行侧写和异常值分析
- 将 BI 报表抽象为一种数据资源,和表这一起管理和分析血缘
- 通过 SQL 监控数据质量
Tweet of the Week
Before modern data warehouses, you used to have to write these awful Hive queries — they took forever to run, and probably returned the wrong answer to your question anyway b/c of poor data quality/modeling.
But today, using modern tools, you can get wrong answers much faster.
以上是本周的推荐,希望对你有用。
你所在的公司在使用什么工具管理 metadata?或有什么妙招来提高各个部门之间的沟通效率?欢迎来信与我分享。
下周见!
Dreamsome
❤️ 想支持《数据科学人》?把它推荐给 3 个朋友吧!
🚀 欢迎用电邮订阅《数据科学人》,我将以周报的形式发布内容