 数据科学人
数据科学人
本期 Newsletter 的主题是 Mess 混乱。
热力学第二定律告诉我们,事物向着混乱与无序发展,今天聊聊数据科学中的混乱。
混乱有时是因为重复,重复同样的工作不仅枯燥无聊,而且会增加后期维护的成本,因为一旦需要修改,处处都需要修改,这就是为什么编程中有一条基本原则叫 DRY(Don't Repeat Yourself)。
混乱有时是因为过度复杂的设计,这种复杂往往是莫须有的,也是难以理解的,这方面的代表人物是美国的漫画家 Rube Goldberg,他的作品都是关于用复杂的方式做简单的小事。
快速变化的环境容易引起混乱,因为缺乏共识,人们就无法形成秩序。但适度的混乱有时不仅仅意味着失控,也意味着挑战与突破,意味着新的灵感的迸发。
以下是本周的推荐。
1. Engineers Shouldn’t Write ETL
这是一篇 2016 年的老文,文章副标题是 A Guide to Building a High Functioning Data Science Department,作者是 Jeff Magusson。
本文指出很多数据科学团队「思考者/行动者」的分工方式导致出现了很多 Mediocre 的工程师,而他们擅长制造混乱:
Mediocre engineers really excel at building enormously over complicated, awful-to-work-with messes they call “solutions”. Messes tend to necessitate specialization.
没有人心甘情愿成为「行动者」,一旦如此划分角色和问题,公司很难留下有追求的工程师,也就失去了改进数据平台的可能,数据科学家创新的步伐也会因为缺少提升效率的工具而暂停。
更好的方式是,让这两种角色的贡献能够容易区分开,并让工程师充分发挥他们的特长:
工程师擅长的是抽象、概括的世界,并在需要的地方找到有效的解决方案。这些问题通常在本质上是横向的。应用约广泛,影响力也越大。他们需要对企业的运作方式有一个整体的理解,但解决方案的抽象性意味着他们对业务逻辑的要求很低,不需要与企业内部的垂直部门建立紧密的合作关系或深入了解。
也就是数据工程师设计乐高积木,数据科学家把它们组装起来。事实上,数据工作流中可以抽象出来的乐高积木除了 ETL 还有很多,比如 Airflow Dag。
2. The problem with AI developer tools for enterprises (and what IKEA has to do with it)
在 Databricks 领导 ML 产品线前,Clements Mewald 曾在 Google 参与了 TFX 的设计。 Mewald 提醒人们在挑选 AI 开发工具时要警惕宜家效应——比起从供应商那里购买开箱即用的东西,人们对自己 DIY 的产品会赋予更多的价值,给它起个好听的名字,写些关于它的博客文章,然后每个人都得到晋升。
有两个主要的原因导致人们认为只要几个工程师就可以从头建立一套 ML 系统。
首先,AI 开发者工具处在一个混沌时期。新技术的出现伴随着新解决方案的涌现,云计算厂商和创业公司都希望自己定义的 API 成为行业标准;业界对 ML 平台从哪里开始、从哪里结束,似乎并没有达成共识,例如,有的平台就不包含数据准备阶段。
人们不知道他们不知道的东西,下面这张图反映了企业在评估机器学习平台时认知与现实之间的偏差。
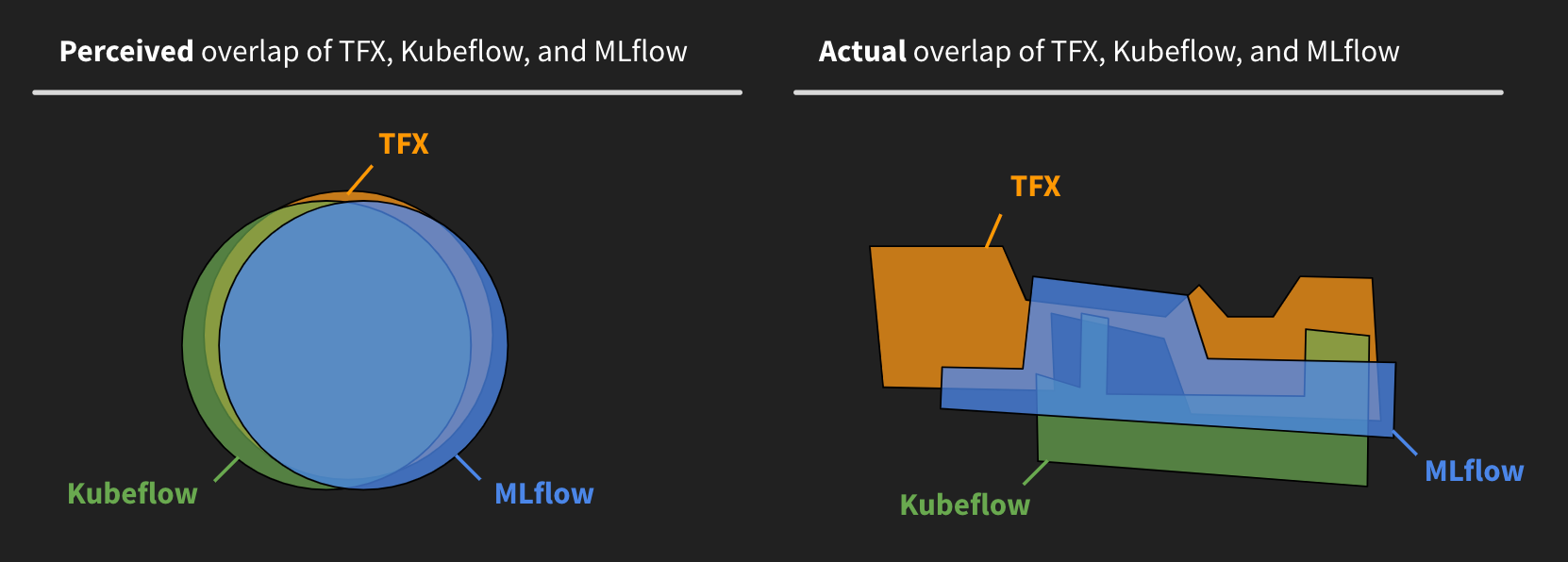
其次,AI 开发工具还存在一个「外观」的问题,Mewald 借用了电子设备中 form factor 这个概念,例如 iPhone 定义了智能手机「外观」,假设 ML 开发的生命周期涵盖:用 Spark 来处理数据、用 Tensorflow 来训练模型、用 Docker 打包、最后用 Kubernetes 来调度 Docker 容器,那么封装这些细节的用户界面应该长什么样子?
I misappropriate this term to summarize everything you would consider when you talk about the “product surface”, “user experience”, or “developer experience”. What do developers actually interact with when we say they are using an ML Platform?
Mewald 的答案是并不存在某种统一的、简化的「外观」,因为不同目标受众的需求是不同的,非常上层的抽象(例如基于 SQL 和基于无代码的 ML 方案)无法满足真实应用场景中对编程灵活度的要求,在迫不得已时反而泄露了更底层的细节,这让我想到了抽象泄露法则和前段时间 ThoughtWorks CTO 对 No-code 的批判。
3. Analytics Is a Mess
本文来自分析产品 Mode 的创始人 Benn Stancil。他提到分析报表和仪表盘的之所以混乱,是因为通过数据寻找问题答案是一个创造的过程。
挑选衡量产品成功的指标时,人们通常会考虑一系列问题,比如,在计算用户数时是否应该排除那些创建了账号但并未使用的用户?每个潜在的指标都会产生一堆分析来评估它,每个分析又会产生更多的问题和新的分支,这是一个创造性的过程,就像写作一样,你永远不知道写的东西是否正确。
正确的胜率不会坐等自己被发现——这个版本不对,那个版本是错的。每个版本都同样准确,因为它们都是胜率的同义词:它们所测量的正是它们所说的,不多也不少。作为分析师,我们的工作不是把数学做对,数学有标准答案,我们的工作是在一组主观的选项中,选择对业务最有帮助的那个。
Stancil 认为这种混乱不仅是可以被原谅的,而且还是进步的过程。这种混乱真是因为我们不知道自己不知道,需要不断提问题才能知道:
We arrive at better answers when we let analysis be generative and spontaneous. Often, the most useful things we find are the things we weren't looking for.
当我们让分析自我生长时,我们会得到更好的答案,通常那些我们还没有开始去找的东西才是我们能够找到最有用的东西。
层层深入和自我生长的分析会带来复杂性,这是一个熵增的过程,但问题是我们缺少对生长过后那棵枝繁叶茂的大树进行修剪的工具。一个类比是编程的过程也是发散的,但同时也包含了收敛的过程,比如抽象、重构,软件工程经过了很多年的发展,沉淀出很多方法和工具来让我们写出更容易维护的代码,但今天分析领域却没有这样的工具。
Tristan Handy 也在自己的 Newsletter 中评论道:
Another thing I’ve been thinking about recently is explicitly creating separate workspaces for curated (production) and messy (experimental, not-yet-production) work. I think one of the challenges Benn is describing isn’t just that analytics is messy…it’s that teams often co-mingle the messy with the clean parts of the process.
Tweet of the Week
Data engineers love building complex Rube Goldberg machines which can be easily replaced with simpler systems that run at a fraction of the original cost.
这是一份关于 Mediocre system 的避坑指南。
以上是本期的推荐,希望对你有用。
本期差点难产,周末有两天在外地度过,大部分文字还是我在返程的火车上写完的,推荐数量比以往更少。
下周见!
Dreamsome
❤️ 想支持《数据科学人》?把它推荐给 3 个朋友吧!
🚀 欢迎用电邮订阅《数据科学人》,我将以周报的形式发布内容