 数据科学人
数据科学人
本期的主题是 self-service。
数据在公司中扮演的基本角色是叙事者:它告诉人们此时此刻正在发生什么——人们更喜欢哪个产品模块?哪个营销活动更吸引人?哪些销售人员完成了业绩?
随着公司变大,分析师不可能回答每一个问题,于是 self-service 似乎成为了公司扩大规模的唯一途径。Gartner 对 self-service BI 的定义是「赋能并鼓励业务人员,在没有 IT 的支持下,自行执行查询和制作报告。」
很多 BI 工具号称,公司里的任何人都可以像专业人士一样分析数据,然而如何把业务上大大小小问题转化为技术的魔法语言,至今仍是一个迷思。有人认为 self-service 就是以拖拖拽拽的方式来写 SQL,也有人管这种方法叫无代码(No-code),另一群人指望 GPT-3 可以解决这个问题,但我认为 self-service 的困难之处恰恰是它表达层以下的部分。
衡量一个问题不仅仅是关于 SQL 语法怎么写,而是定义这个问题所需要知道的一切上下文。例如,在计算商品平均订单量时,是否要排除那些用礼品卡购买的订单?又比如,NPS 多少分以上代表「非常满意」?有时候复杂性也来自于外部世界,比如一周的第一天是周一还是周日?它们往往由一段特殊的计算逻辑构成,这些逻辑也就是我们常说的口径,只有经验最丰富的分析师对它们之间微妙的区别了然于心。
另一方面,随着越来越多的人开始利用数据提出自己的问题以后,如何保证所有人对同一个问题使用相同的衡量标准,是我们每个和数据打交道的人今天所遇到的最大障碍。
以下是本周的推荐。
1. Why is self-serve still a problem?
本文道出了 self-service 失败的真相,作者 Benn Stancil 是流行 BI 工具 Mode 的创始人和首席分析官。
今天的 BI 工具都基于这样的一个框架:它们假设 self-service 可以帮助任何人像分析师一样去探索数据,于是乎 self-service BI 在某种程度上看起来像是数据分析的无代码版本。
这个想法彻底错了,因为它定义错了问题,在 Stancil 看来,业务人员和分析师的工作性质决定了他们无法合二为一,同样都是和指标打交道,但他们的区别有点像科学家和记者:
当你问分析师一个问题时,他们的第一个想法往往是「我们怎么才能衡量这个问题?」 他们像科学家一样工作,创建新的数据集,并用新的方式汇总数据,提出具体的假设并得出结论。而业务人员的工作像是记者,他们通过整理现有指标,从全局考虑问题得出结论。他们并非寻找新的方法来评估问题,他们的第一个想法往往是:「我们现在是怎么衡量这个问题的?」
业务人员的需求是提取指标,而不是一个用来从任何可能的角度探索数据的 BI 产品。self-service BI 不是要提供无限的表达能力,让业务人员的创造力得到发挥,相反,他们需要的是一个有限的 KPI 列表:
A better solution recognizes what that majority wants: metric extraction. They want to choose from a list of understood KPIs, apply it to a filtered set of records, and aggregate it by a particular dimension.
与其让工具适应我们的每种需求,不如斟酌这些需求是否真的需要。我们应当学习 Fivetran 和 Stitch 这样的 ELT 工具,它们早期的版本提供了比传统 ETL 供应商更少的功能,它们赢了。Stancil 说:
Opinionated simplicity is better than indifferent optionality.
有主见的简单性好过中立的可选性。
2. The missing piece of the modern data stack
紧接着来看 Benn Stancil 最近的一篇文章,他提到了 Modern Data Stack 缺失的一隅:self-service 需要的不是更好的 UI,而是一层 Metrics layer 抽象。
所谓抽象,就是对高层屏蔽低层细节。引入 Metrics layer,意味着使用指标的人不需要关心一个指标是怎么来的,只需要用文本描述想提取哪个指标。它向 self-service 用户隐藏的不是构建查询的复杂度,而是指标计算的逻辑,业务人员只需要做选择,而非创造。关于抽象,一个经典的说法是「计算科学中的所有问题都可以通过增加一层抽象来解决」。
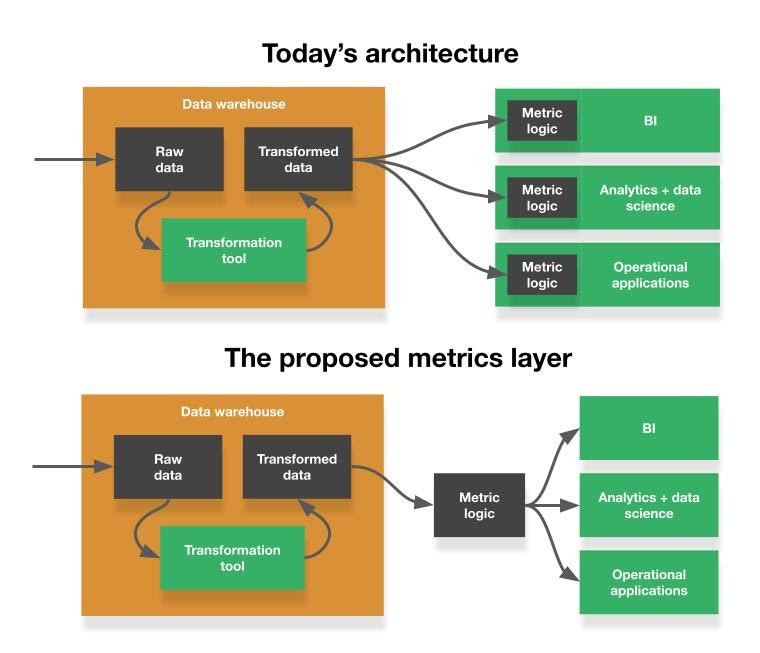
他分析了指标口径在今天的 BI 中很难保证一致性的原因:
Without a rollup to draw from, data consumers have to follow the second path: aggregate new metrics directly from dimension tables. That leaves the nature of the aggregation up to the person doing the analysis, and these aggregations are rarely simple. [...] While all of this logic might live in the rolluporders table, it isn’t necessarily in the dimensionorders table, meaning someone has to apply it on their own to do their analysis. This makes it incredibly difficult for people, especially people who aren’t analysts and aren’t familiar with the weird nuances that riddle most datasets, to consistently arrive at the same result.
如果没有现成的汇总表,就只能选第二条路,直接从大宽表中聚合新的指标出来,这就等于是把汇总的活留给了做分析的人,而这些活往往不易。[...]虽然这些逻辑有可能出现在汇总后的订单表中,但大宽表中不一定有这些信息。这意味着有人必须在自己的分析中实现这些逻辑,导致人们很难保证一致的口径,尤其是那些不了解数据集之间细微差别的非分析人员。
每次从大宽表中进行聚合,意味着指标定义分散在不同人的不同仪表盘中,无法共享。虽然一些 BI 工具(比如 Looker)提供了抽象机制,但仍然无法跨工具共享指标。如果有一层 Metrics layer,我们将在不同的系统中共享计算指标逻辑,无论是 BI 还是数据科学场景,这样就自然解决了一致性的问题。
有人可能会问,为什么不从汇总表中提取指标?因为汇总表需要提前 rollup,不够灵活,通常只能事先加工出一级指标,比如活跃用户数,而面向 self-service 的分析,需要观察更细粒度切片,例如 Apple 手机用户的日活。
3. “How do you decide what to model in dbt vs LookML?”
作为咨询公司 Fishtown Analytics 的创始人,Tristan Handy 在多年给客户实施 BI 的过程中,发现 Looker 是所有想实现 self-service 公司的最好选择。
本文同样指出汇总层无法满足 self-service 需求的原因:
BI 工具的所有意义在于,让不熟悉数仓和不知道怎么写 SQL 的用户,能够提出自己的问题,然后 BI 工具能够即时回答这些问题。这意味着你需要让你的 BI 工具以适合的粒度访问数据,让用户能够真正做出有意义的选择。然后,当用户应用了他们选择的任何过滤和分组后,最后由 Looker 来运行 sum(amount) 查询来获得收入。
4. Headless Business Intelligence
本文来自风投公司 Base Case 的两位创始人,介绍了 Headless BI(无头 BI)的概念。
BI 工具在设计之初只是为了实现一个目的——指标的可视化,它假设数据的终端用户只有分析师,而数据是为人工决策提供信息,这显然已经无法适应今天的情况。
首先,我们无法在除 BI 工具以外的其他地方使用数据, 例如,在一个用户快要流失时,通过电子邮件向他提供免费服务,或在一个用户余额即将用完时,通知销售人员进行触达。
其次,由于指标的计算逻辑可能存在于不同地方,增加了不同团队之间的摩擦力,例如,算法团队会将某个业务指标作为模型的优化目标。
Headless BI 通过将指标 API 化,将指标定义与可视化解耦:
通过 Headless BI,产品经理可以在不用写 SQL 的情况下定义这个复杂的逻辑,甚至在通过 UI 完成。然后,他们可以将 BI 工具都指向这个逻辑,可视化日活随时间变化,或将其与行业或用例这样的信号相关联。他们甚至可以与工程、设计部门合作,建立产品功能,通过 API 消费这个信号。
5. The Problem With Hands-Off Analytics
这是一篇 Benn Stancil 唱 self-service 反调的文章。虽然 self-service 可以解决企业规模化的问题,但与分析师提供的价值背道而驰。
Stancil 说「把仪表盘交给产品经理或营销人员,让他们自己做决定」不是分析:
To put it another way, the only things self-serve helps scale is SQL code and a general understanding of business logic. But knowing how to write a query, or how our company defines a new customer, isn't what makes an analyst. We're analysts because, when there are problems, we know which rocks to look under, how to question what we find, and how to distinguish between what we've learned and what we haven't.
Project of the Week
在 Stancil 发布了关于 Metrics layer 的建议之后没多久,Airbnb 就公开了他们内部的指标管理平台——Minerva(古罗马神话中的智慧女神)。
Minerva 的产品愿景是让指标「一次定义,到处使用」。在 Minerva 中创建的指标,可以在公司的仪表盘工具中访问,也可以在我们的 A/B测试框架中跟踪,或被异常检测算法处理,以发现业务异常。在过去的几年里,我们与其他团队密切合作,创建了一个建立在 Minerva 之上的工具生态系统。
Stancil 很快进行了回应,他给我的一个启发是,一个位于业务上游的产品,很难以 API 的形式整合进一个工具生态,因为需要每个供应商都与它进行集成才行,尤其这还是一个用来解决口径一致问题的专门层,最好的方式还是像 dbt 那样对下游消费者保持透明。
Tweet of the Week
@tayloramurphy 问「你们最保守的数据观点是什么?」,以下是赞数最高的两条回复:
Self-serve ice cream is fun but I don’t don’t let my toddler serve himself.
self-serve analytics/BI is dangerous