 数据科学人
数据科学人
本周的主题是 Normalization (规范化)。
在数仓建模中,Normalization 表示规范化,数据库根据其规范化程度,有着不同范式级别,从第一范式到第四范式。Snowflake 模型的规范化程度更高,它的优点是数据冗余少,缺点是在使用时需要写更多 join。而 Star 模型规范化程度更低,通过牺牲存储空间,它换来了更好的查询性能,它的缺点是不够灵活,更新起来不方便 。
在机器学习领域,Normalization 是一种能让不同特征能够有相似的取值范围从而加速模型收敛的技术,有时也被称作归一化。
以下是本周的推荐。
1. dbt and the Analytics Engineer — what’s the hype about?
本文解释了 dbt 工具的流行和 analytic engineer 的崛起背后的原因。
首先是技术上的变化,当云数据仓库上能跑 transform 类型的任务时,我们就可以直接使用 SQL 把原始数据转化为更加干净、定义更加明确的数据模型,而不依赖于编写特定的程序:
The shift from ETL to ELT means people who know SQL have the power to transform and clean data once it arrives in the warehouse. Cloud data warehouses are powerful enough to handle the transformation workload.
而在过去 ETL 的范式下,我们很难招到这样的人,因为他们需要成为软件工程师和数据分析师的混合体,既了解业务也懂技术,而现在分析师可以自己完成这一步,只需要会 SQL 就行,2021 年最受欢迎的 25 种数据工程师技能中,SQL 排名第二:
也因为这个趋势,dbt 已经成为了对现代云原生数据仓库进行 transform 的事实上的规范,分析师在 dbt 中用 SQL 来生产模型,并且在另一个工具中使用 SQL 来消费数据:
Tools like dbt enable analysts with SQL-based workflows and give them the picks and shovels to work like software engineers do.
2. 10 Common Mistakes When Building Analytical Data Models
这篇文章总结出了建模过程中常见的 10 种错误,其中有一条是关于规范化的。
作者提到 Snowflake、Star 和 Data Vault 这些建模技术是在存储昂贵的年代提出的,今天的存储和计算相对来说可能没有那么昂贵了,相比之下人力成本可能是更需要考量的因素。一个例子是 2000 年提出的 Data Vault 理论,所有的表都需要被分成 hub、satellites和 links:
Similarly, when you adhere to the data vault modeling, you would split every table into hubs, satellites, and links, even when there is no logical reason to do so for a specific use case. While rigor is desirable in engineering, all data modeling techniques are a set of guidelines rather than hard rules that should be blindly followed.
这种高度规范化的设计当初是为了提高数据摄取时的性能,但缺点是不得不在查询时引入很多繁琐的 join:
Data design that requires an extensive number of joins, such as data vault, may provide faster data ingestion due to parallel loads, but it often hurts query performance and, for many, is quite unpleasant to work with.
可能有人会说,我们可以使用视图来降低查询的复杂度,但是创建很多视图本身会让找到想要的数据变得更困难。
我认为数据建模的意义不只是为了提升查询性能,而是把机器能读懂的数据汇总到人能够理解的维度,让使用者在需要用到某个数据时能更快速地找到它,甚至它指引人们哪些数据和指标是更重要的。
3. What Have Language Models Learned?
这是谷歌人工智能实验室出品的一篇博客文章,介绍了语言模型 BERT 是什么。
为了展示语言模型的用途,第一个段落展示了一个 BERT 的例子,你可以输入一个句子,然后隐藏其中任何一个单词,让 BERT 来完形填空,我在这里输入了 Fire and Blood(《权力的游戏》中坦格利安家族的家训 ):
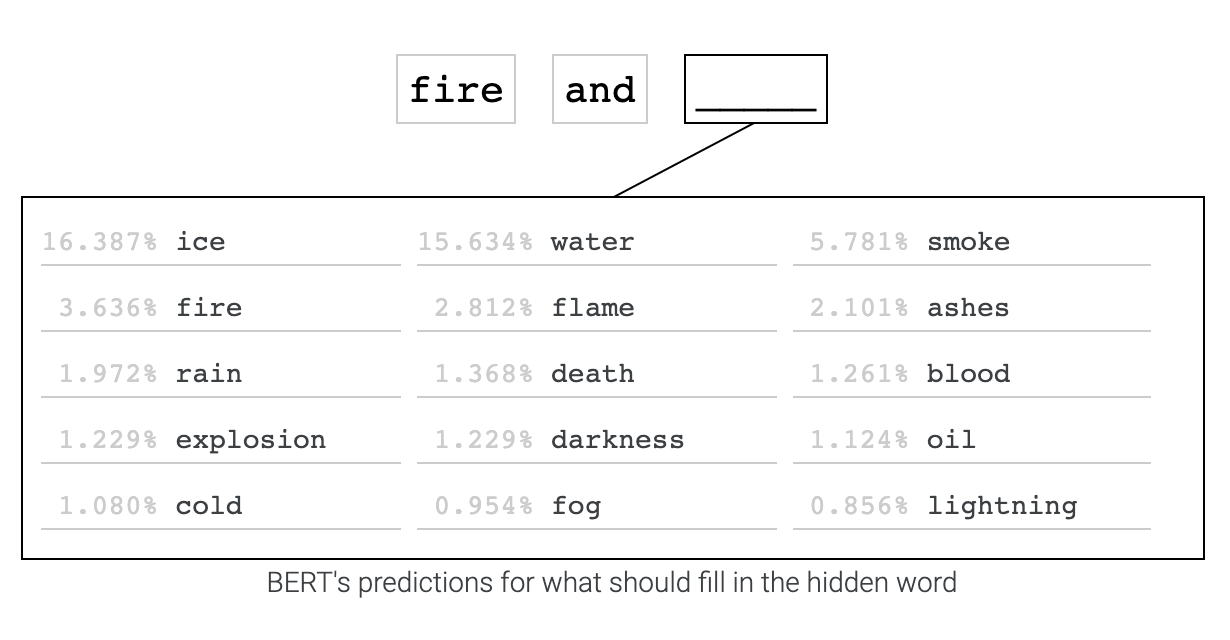
BERT 认为 fire 后面紧接着出现 ice 的概率最高,其次是 water 和 smoke,这是 BERT 在对书籍和维基百科学习后进行训练给出的预测。通过比较同一个单词在两个不同句子中被 BERT 推荐的概率,我们可以学习到一些有用的模式。
例如,通过 We went to Texas/New York and bought _ ,可以观察到去这两个地方的人买商品的习惯;通过 Lauren/Elsie was born in the year of _ ,可以预测叫哪个名字的人年纪更大;而 The new doctor/nurse was named _ 一定程度上可以反映职业和性别之间的某种微妙联系(人名有一定的性别化特征)。
可能你已经发现了,语言模型的缺点是它会延续甚至是放大人们的刻板偏见(stereotype),一个基于 BERT 的征信模型在用于放贷时会有性别歧视,也更可能把穆斯林和炸弹联想到一起。Yann Lecun 曾说过,如果数据有偏见,那么 ML 系统就会有偏见。语言是我们思维的体现,当我们在马路上看到一辆失去控制的汽车时,是否会下意识地会认为开车的人是一名女司机呢?偏见同样可能会以数据的形式出现在训练数据中。
文章介绍了一些方法来尝试消除 word embedding 模型中所蕴含的偏见,例如对于所有出现性别代词的句子,同时添加一份替换为其同义词的句子,这让我想到了在机器学习中我们经常需要对数据进行重新采样(resampling)来消除偏见,这也可以被看成是某种对数据的规范化。
4. How to Build a Production Grade Workflow with SQL Modelling
本文来自 Shopify 团队分享的在用 dbt 进行数据建模时的一些最佳实践,他们团队的规模大概在十几人左右。
首先,dbt 在一个中央 sources.yml 中声明数据源,它很快就会变成一个很大的文件,不同团队如果在各自的 PR 中都修改它,合并代码就会很困难,于是他们把 sources 改为了层级结构。
接着,他们利用 dbt staging 的概念创建了一个基础模型层,用来防止数据加工逻辑侵入应用层代码,如重命名字段、洗数据和类型转换。
最后,他们为代码仓库建立了 CI(持续集成),每次提交代码时都会把所有模型实例化为临时视图,一旦创建视图失败就会报错,说明要么是上游的模型少了某个列,要么说明当前的 SQL 出了什么问题,在验证结束后会删除所有视图。
CI 除了可以验证模型的正确性,还可以在静态检查应用一些特殊规则,这些规则可以强制要求修改者遵循某种规范,例如,模型的每一列都必须符合事先约定好的命名规范,或只允许基础模型层的表直接引用 source,而这也是 dbt 提倡的最佳实践之一。
Tweet of the Week
The hardest problem in data is data modeling and should always be data modeling. The whole goal of this wave of data infra startups (Fivetran, Hightouch, dbt, etc.) should be to make data modeling the only challenge remaining.