 数据科学人
数据科学人
本周的主题是 Data team 数据团队。
1.Building a data team at a mid-stage startup: a short story
我在上期 Newsletter 中推荐了 DevOps 圣经《凤凰项目》,巧合的是本周 Erik Bernhardsson 用相同笔法,以第二人称视角讲述了在中型创业公司中一手建立数据团队的故事,非常精彩!值得一读。Bernhardsson 曾是 Spotify 推荐系统的工程师,也是开源任务调度工具 Luigi 的作者。
故事的背景是你被带到了一家处于中期阶段的创业公司,负责发展一个小型数据团队——一个只有 4 个人的小团队,而你得到的预算是在年底前将其发展到 10 个人。
工作的第一天,你就发现公司还在使用电子表格计算对供应商的付款,并通过 VLOOKUP 来拼凑出「模型」,数据分散在不同的系统里,同时管理层对数据团队的工作预期也很模糊,业务团队会雇佣数据科学家,但没有明确的业务目标,产品团队用来衡量标准的指标不一致,也不打算使用 A/B 实验。
种种迹象表明,这不是一家数据驱动的公司。
你做的第一件事就是把数据放在了一个地方,让所有人能够查询。但并不是所有团队都理解数据团队可以为他们建立什么,遇到问题时也不知道该问谁。于是你改变了管理方式,让手下的业务分析师加入不同团队,与他们一同工作。这种组织结构保证了数据和决策之间创造了一种更紧密的反馈循环——如果每个问题都经过一个节点,那么沟通成本就会很高,分散化以后可以更快地进行迭代,同时每个人还能够发展出有用的领域技能。但他们还是汇报给你,因为专业数据人员不希望向不懂数据的业务人员汇报。
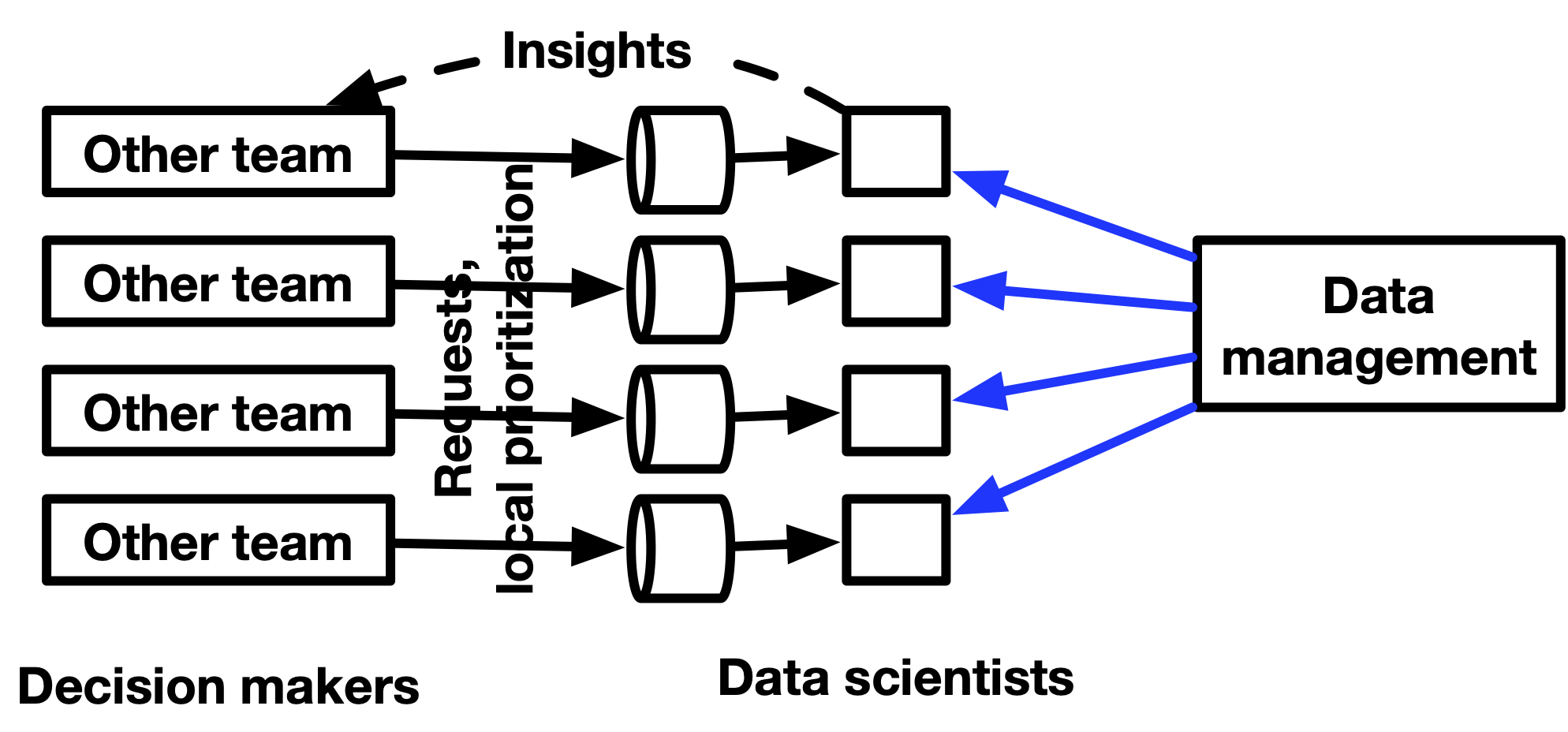
随着工作的进行,CEO 也开始推动团队使用数据作为真理,产品团队也尝试起了 A/B测试,人们开始更加关注指标,数据团队的工作就变成了为不同层级提供不同的服务,例如,为高层定义并计算高质量的指标,并分解为不同团队的子指标。
随着业务分析师嵌入到不同团队,对数据科学的需求也愈来愈大。与此同时技术债也越来越多,你发现不得不转换各种衍生数据集来让查询更加容易和更稳定,但最终你成功地将组织转型为数据「原生」型组织……
2. Building The Modern Data Team
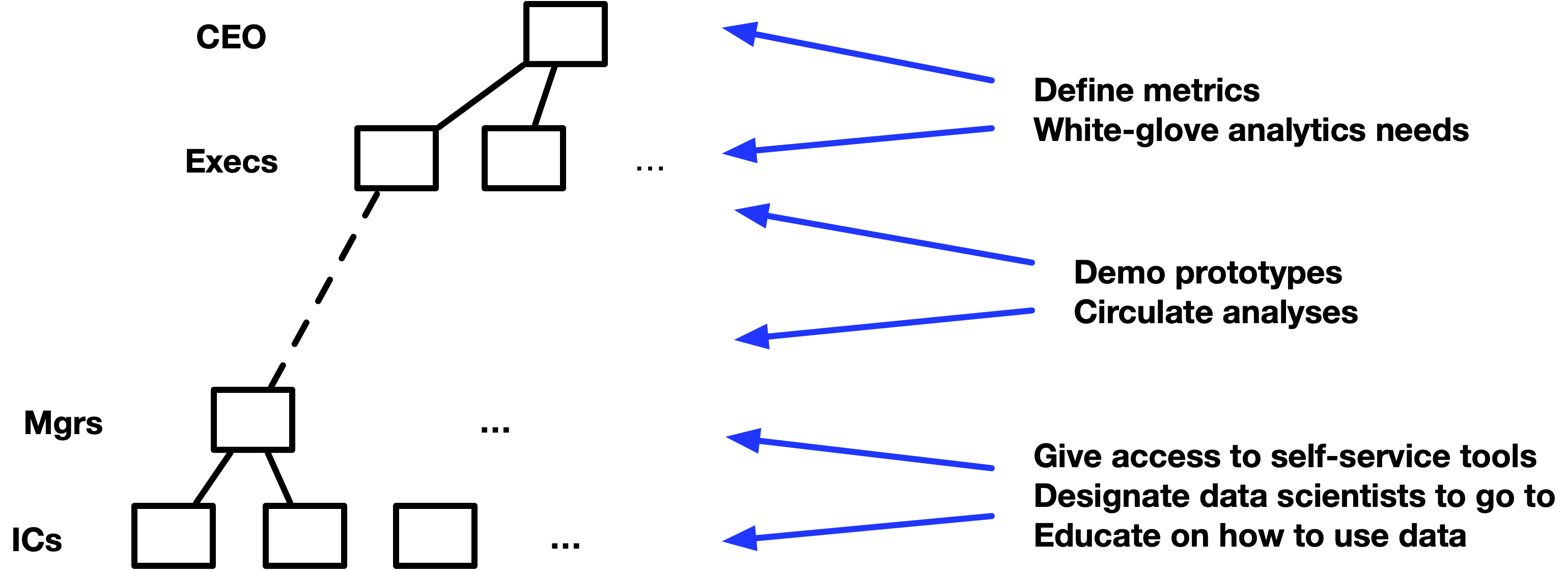
本文提到了数据团队经常遇到的管理问题,Pedram Navid 认为数据团队在敏捷开发的过程中会容易丧失热情,并且变得平庸。在敏捷开发中,Stakeholder 并不会让所有人都参与到工作优先级制定的讨论当中,也来不及向所有参与工作的人阐述新工作的重要性,他们通常将分析师的工作当做一个黑盒,并指派工作任务,例如制作一个归因分析报告。
Stakeholder 往往不能坐下来做最难的工作,写下他们要完成的任务,他们将如何衡量它,以及为什么他们认为它很重要。相反,他们要求分析师提供一份归因报告,结果是分析师需要花费大部分时间在数据发现和收集需求的工作上。我们如何确定归因?我们能接受准确性是什么?我们将用这些数据做什么?我们要如何分析它?将销售归因在营销活动上意味着什么?分析结果将如何影响我们的决定?它对产品产生的基本价值是什么?这些才是我们所需要回答的真正问题,但敏捷开发并不允许我们提前对这些问题进行回答。
Navid 说,数据分析师应该在新功能规划的早期就参与进来,并授权他们做出贡献,他们可能会提出更有价值且尚未解决的事项,他们可能有比在「Excel 表格上增加一列」更好的方法来解决业务问题,他们可能会认为团队正在解决错误的问题,虽然他们也可能是错的,但至少他们在场,并参与其中。否则,数据团队会彻底沦为雇佣兵,奔命于在众多优先级定义模糊的任务之间。
如果新的工作不能解决现有的瓶颈,则应该对 Stakeholder 说不,因为如果他们无法回答做要做事情的意义,说明要么问题没有定义清楚,要么事情不够重要。
If a stakeholder is not able or not willing to answer the hard questions about why they want something done, then the work is either not clear enough or not important enough for a data team to work on.
3. What I've learned about data recently
本文来自 Netlify 数据分析师 Laurie Voss,他总结了自己在数据岗位工作了 10 之后学到的东西,而在此之前他一直是 Web 开发工程师。
首先,数据团队不应该自己自己折腾数据仓库,而是应该直接使用现有服务供应商的数仓产品:
除非你的公司做的是运行数据仓库,否则你应该从其他人那里购买数据仓库。不为数据仓库服务付费而节省的任何资金,都将被你用于操作数据仓库的工程时间所消耗,而且它永远不会像专家运行的那样快速和可扩展。
其次,一个标准化的框架有助于团队以相同的方式工作,从而降低摩擦,一个类比是 Web 开发,在 Ruby on Rails 这样的框架出现之前,两个人会选择不同的方式完成同一件事,所以他们会为此争吵,或者误解代码是如何工作的。
This changed -- at least for me -- around 2006, when I heard about Ruby on Rails. Ruby is not my favorite language, but Rails was a revolution. Rails provided an opinion about the Right Way To Do It. It wasn't necessarily always really the best way to do it, but the surprising lesson of Rails is everybody doing it the same way is, in aggregate, more valuable than everybody trying to pick the very best way.
Rails 的框架维护人员主要负责架构,你可以专注于业务逻辑,而不是花费一半的时间来解决架构中的错误。结果是单个开发人员的工作大大减少,Web 开发的步伐大大加快。
Rails 的革命和随之而来的框架风暴是你可以雇佣一个已经知道你的网站如何运作的人加入你的公司。
在一个高速发展的行业中,从业人员的一定是供不应求的,因此 dbt 和 Airflow 这样的框架最大的价值是标准化,它们是可以跨公司使用的通用技能,并且很容易找到插件来拓展功能。数据团队在选择工具和技术方案时也应该考虑到这一点,而不是盲目地追求最佳方式,那样反而是一种 Ego。
Tweet of the Week
"Building dashboards is easier than knowing what to put in a dashboard."
以上是本周推荐,感谢你的阅读!
Dreamsome
本周我们开源了一个数据分析相关项目——Tellery。我们认为大部分 BI 工具,要么专注于仪表盘展示,要么旨在让业务人员以自助的形式提出问题,很少有工具以协作为核心。很多分析是一次性的,我们在一个画板上写下 SQL 执行,把结果复制到可视化工具中画图,然后将图表复制粘贴到 PPT 中,下次重新开始;相同 SQL 代码重复了很多遍、很多个地方;不同人定义指标的口径可能不一样;随着周围业务的变化仪表盘里的分析很快就变得陈旧,维护它们是一件非常痛苦的事情……Tellery 试图解决这些问题。
下周见!
❤️ 想支持《数据科学人》?把它推荐给 3 个朋友吧!
🚀 欢迎用电邮订阅《数据科学人》,我将以周报的形式发布内容